
Facebookを単なるソーシャルメディア企業と考えるのはもうやめよう。ドローンを使ったインターネットサービスの提供、バーチャルリアリティのためのOculusの買収、そして人工知能(AI)の継続的な追求など、Facebookは急速に世界最先端の技術研究センターの一つへと成長した。
Facebookだけではありません。GoogleやIBMといった企業も同様の計画を掲げており、この分野全体の開発は加速しており、人工知能が人間とコンピューターの関わり方を間違いなく形作る段階に達しています。実際、既に人工知能は人間とコンピューターの関わり方を形作っていますが、それは水面下で静かに行われています。Facebookはこの技術に大きな関心を寄せており、月間15億人のユーザーにサービスを提供しています。同社は汎用知能のエミュレーション、つまりコンピューターを線形で論理的な機械ではなく、自由な人間のように考えさせるという課題に、多角的なアプローチで取り組んでいます。Facebook人工知能研究チーム(FAIR)が汎用AI問題の解決に取り組む一方で、Language TechnologyやFacebook Mといった小規模なグループは、実用的な機能をユーザーに提供しています。
Facebookにおける人工知能研究の誕生
すべては2013年に始まりました。Facebookの創設者兼CEOのマーク・ザッカーバーグ氏、最高技術責任者のマイク・シュローファー氏、そして他の経営陣は、ほぼ10年前の創業以来の同社の業績を評価し、今後10年、20年にわたって繁栄するためには何が必要かを模索していました。
Facebook は、すでにその大人気ソーシャル ネットワークで機械学習を使用して、ユーザーがニュース フィードに何を表示するかを決めていましたが、当時の最先端のニューラル ネットワークに比べれば単純なものでした。
Facebookのエンジニアの中には、畳み込みニューラルネットワーク(CNN)の実験を行っていた者もいました。CNNは機械学習の中でも強力な手法であり、現在では画像認識に広く利用されています。ザッカーバーグは、初期段階から人工知能の可能性に強い関心を抱き、Google Brainのエンジニア、マーク・アウレリオ・ランザートを雇用しました。そして、CNNの発明者であるヤン・ルカンのもとへ足を運びました。
現在FAIRの所長を務めるヤン・ルカン氏は、人工知能研究において輝かしい経歴の持ち主です。1988年にベル研究所(電話の父、アレクサンダー・グラハム・ベルによって設立され、通信とテクノロジーの多岐にわたる分野にわたる実験で知られています)で研究者としてキャリアをスタートさせ、その後AT&T研究所の部門長を務め、2003年にニューヨーク大学で教鞭をとるまで務めました。現代の畳み込みニューラルネットワークは、ルカン氏のキャリアにおける研究の集大成です。ATMがどのようにして小切手を読み取るのか、不思議に思ったことはありませんか?それがルカン氏の功績です。彼の初期の研究には、1996年に公開された「SN」と呼ばれるニューラルネットワークシミュレーターが含まれていました。

「シュレーファーとマークと話し始めました。私の話が気に入ったようです」と、ルカン氏はポピュラーサイエンス誌のインタビューで語った。「そして、彼らは私に運営を任せようと説得してきました…マークのような人がやって来て、『ああ、わかりました。あなたはほぼ自由裁量権を持っています。あなたは世界クラスの研究室を立ち上げることができます。そして、AI分野で世界最高の研究室を築くことを期待しています』と言ってきたら、『ふーん、興味深い挑戦ですね』と言うでしょう」
ヤンは、世界クラスの研究所がどのようなものになるかについて、いくつかのアイデアを持っていました。例えば、優秀な人材を引き付けたいのであれば、野心的な長期目標を掲げた、野心的な研究所が必要だ、と。そして、研究内容についてはある程度の自由を与え、非常にオープンでなければならない、と。「これはFacebookの哲学、つまりオープンであることの哲学と合致していました」とルカンは言いました。
チームの編成
Facebookの未来を創造する任務を負ったチームは、わずか30名ほどの研究者と15名のエンジニアからなる小規模な組織です。業務は3つの部門に分かれています。Facebook AI Researchの本社はニューヨーク市アスタープレイスにあり、ルカン氏は約20名のエンジニアと研究者を擁しています。メンロパーク支部にも同数のスタッフが勤務しています。また、6月にはFAIRがパリに約5名の小規模オフィスを開設し、フランスのコンピュータサイエンスとオートメーションの研究所(INRIA)と連携しています。Facebook内には、言語技術チームなど、AIの導入に取り組んでいるチームが他にも存在し、FAIRはその研究部門です。
これらの研究者やエンジニアはテクノロジー業界全体から集まっており、多くは以前ルカン氏と共同研究を行っていました。高度な人工知能研究はそれほど大規模な分野ではなく、ルカン氏の教え子の多くはAIスタートアップの起業に携わり、後にTwitterのような大企業に吸収されています。
ルカン氏はかつてWired誌に対し、ディープラーニングは「ジェフ・ヒントン氏と私、そしてモントリオール大学のヨシュア・ベンジオ氏による陰謀だ」と語ったことがある。ヒントン氏はGoogleでAI研究に携わり、ベンジオ氏はモントリオール大学とデータマイニング企業ApStatで時間を分け合っているが、ルカン氏は他の一流の人材を獲得することに成功している。
「ベル研究所で初めて部門長に任命されたとき、上司は私にこう言いました。『覚えておくべきことは二つだけ。第一に、自分のグループ内の人と決して競争しないこと。第二に、自分より優秀な人だけを雇うこと』」とルカン氏は語った。
言語に関する研究サブグループを率いるレオン・ボットー氏は、ルカン氏の長年の同僚です。彼らは1987年からAmigaOSの開発に携わり、ニューラルネットワークシミュレーターを共同開発してきました。ボットー氏は2015年3月にFAIRに加わりましたが、それ以前はMicrosoft Researchで機械学習と機械推論の研究に携わっていました。

ルカンは2014年11月、ウラジミール・ヴァプニックをコンサルタントとしてチームに迎え入れました。ヴァプニックとルカンはベル研究所で共に働き、機械学習の能力を測定する手法を含む、機械学習に関する形成的研究を発表しました。ヴァプニックは、既存のデータに基づく予測という側面を扱う統計学習理論の父です。人間にとっては単純な作業のように見える予測は、実際には先入観や世界に対する観察の膨大なライブラリに依拠しています(これについては後ほど詳しく説明します)。この分野のリーダーであるヴァプニックは、知識伝播への関心を持ち、教師と生徒の相互作用から得られるヒントを機械学習に適用する研究を続けています。

目標
チームの規模と学術的重みにより、Facebook は長期目標を野心的に達成することができ、その目標は LeCun 氏が「紛れもなくインテリジェント」と呼ぶシステムに劣らないものとなっています。
「今のところ、最高のAIシステムでさえ、常識がないという意味で愚かです」とルカン氏は述べた。彼は、私がボトルを手に取って部屋を出て行くという状況について語った。(私たちはニューヨークのFacebook会議室にいて、「ゴーザー・ザ・ゴーザーリアン」という名前だ。ゴーストバスターズの悪役と同じ名前だ。真の機械知能の誕生について議論する部屋としては、不吉な名前だ。)人間の脳は、誰かがボトルを手に取って部屋を出て行くという単純なシナリオ全体を難なく想像できる。しかし、機械にとっては、その前提だけでも膨大な量の情報が欠落していることになる。
ヤンは、私が頭の中で状況を想像すると、「文章の中では言っていませんが、あなたはおそらく立ち上がったでしょう。ドアを開け、ドアを通り抜け、もしかしたらドアを閉めたかもしれません。ボトルは部屋にはありません。つまり、現実世界の制約を知っているからこそ、そこから多くのことを推測できるということです。だから、私があなたにそれらの事実をすべて伝える必要はないのです」と言います。
人工知能コミュニティは、機械がどのように学習してこのレベルの推論を実現するかについて、現時点では十分な知識を持っていません。この目標達成に向けて、Facebookは周囲の世界を理解できるほど十分に学習できる機械の開発に注力しています。
ルカン氏によると、最大の障壁は「教師なし学習」と呼ばれるものだ。現在、機械は主に1つか2つの方法で学習している。1つは教師あり学習で、システムに犬の写真を何千枚も見せ、犬の特性を理解するまで学習させる。この手法はGoogleのDeepDreamで説明されており、研究者たちはそのプロセスを逆転させることでその有効性を明らかにした。
もう1つは強化学習です。これは、コンピューターに識別すべき情報を与え、それぞれの判断に対して「はい」か「いいえ」の答えだけを与える学習です。この学習には時間がかかりますが、機械は内部構成を強制的に構築するため、この2つの学習形式を組み合わせることで堅牢な結果を得ることができます(DeepMindがAtariをプレイしていたのを覚えていますか?)。教師なし学習はフィードバックや入力を必要としません。ルカン氏によると、人間はまさにこれと同じように学習します。私たちは観察し、推論し、それを知識の蓄積に加えます。これは非常に難しい問題であることが証明されています。
「これを構築するための基本原則すらまだありません。もちろん、取り組んでいるところです」とルカン氏は笑いながら言った。「アイデアはたくさんあるのですが、うまく機能していないんです。」
真に知的なAIに向けた初期の進歩
しかし、進歩がないわけではありません。現在、ルカン氏は、既存の畳み込みニューラルネットワークに統合することで情報保持能力を付与できる「記憶」ネットワークの研究に熱心に取り組んでいます。彼は、この新しい記憶保持モードを、海馬と大脳皮質がそれぞれ支配する脳の短期記憶と長期記憶に例えています。(ルカン氏はCNNを脳に例えることを実際には嫌っており、むしろ5億個のノブを持つブラックボックスモデルを好んでいます。)
メモリモジュールにより、研究者はネットワークにストーリーを伝え、後でそのストーリーに関する質問に答えさせることができます。
ストーリーには、J・R・R・トールキンの『指輪物語』が使われました。もちろん、全巻ではなく、主要なプロットポイントの短い要約です(「ビルボが指輪を奪った」)。物語の特定の時点で指輪がどこにあったかという質問に対して、AIは簡潔かつ正確な答えを返すことができます。CTOのマイク・シュローファー氏によると、これは物体と時間の関係を「理解」しているという意味で、Facebookがユーザーが見たいものをより正確に表示できるようになるとシュローファー氏は強調しました。
「世界の文脈を理解し、人々が何を望んでいるのかを理解するシステムを構築することで、私たちはそのお手伝いをすることができます」とシュローファー氏は3月の開発者向けプレゼンテーションで述べた。「私たちは、誰もが本当に大切なことに時間を費やせるようなシステムを構築できるのです。」
FAIRチームは、「Embed the World」というプロジェクトを中心に、このコンテキストを開発しています。機械が現実をより深く理解できるよう、FAIRチームは画像、投稿、コメント、写真、動画など、あらゆるものの関係性をベクトルで表現することを機械に教えています。ニューラルネットワークは、類似したメディアをグループ化し、異なるメディアを距離を置くことで、複雑なコンテンツの網を構築します。この様子を視覚的に理解するのに役立つ動画があります。

このシステムによって、「推論を代数に置き換える」ことが可能になる、とルカン氏は言う。そして、これは非常に強力だ。Embed the Worldプロジェクトで開発された人工ニューラルネットワークは、同じ場所で撮影された2枚の写真を、写真の視覚的な類似性に基づいて関連付けることができるだけでなく、テキストがそのシーンを説明しているかどうかも判断できる。これは現実の仮想記憶を再現し、それを他の場所や出来事の文脈にクラスタリングする。過去の「いいね!」、興味、デジタル体験に基づいて「仮想的に人物を表現」することさえできる。これはまだ実験段階だが、Facebookのニュースフィードに大きな影響を与え、ハッシュタグの追跡に限定的に利用されている。
長期的な目標については多くの議論が交わされていますが、その過程で積み重ねられた小さな成功がFacebookを着実に賢くしてきました。2014年6月には、「DeepFace:顔認証における人間レベルの性能へのギャップを埋める」と題した記事を発表し、顔認識の精度が97%以上であると主張しました。ルカン氏は、Facebookの顔認識技術は世界最高水準であると確信しており、それがFacebookと学術研究機関との重要な違いだと述べています。現在、DeepFaceはFacebookの写真自動タグ付けの原動力となっています。
「実際に機能するアイデアがあれば、1か月以内に15億人の目に届く可能性があります」とルカン氏は述べた。「長期的な目標である地平線に目を向け続けましょう。しかし、その途中で、短期的に応用できるものをたくさん構築する予定です。」
ニューヨーク大学とMITのコンピュータサイエンス・人工知能研究所で長年研究を重ねてきたロブ・ファーガス氏は、視覚に関するAI研究チームを率いています。彼のチームの研究成果は既に写真の自動タグ付けに表れていますが、ファーガス氏によると、次のステップは動画だとのことです。多くの動画はメタデータが不足しているため、あるいは説明文が付いていないために、ノイズに埋もれてしまっています。AIは動画を「観察」し、動画を恣意的に分類できるようになるでしょう。
これは、ポルノ、著作権で保護されたコンテンツ、その他利用規約に違反するコンテンツなど、Facebookがサーバーへの流入を望まないコンテンツを阻止する上で大きな意味を持ちます。また、ニュースイベントを特定したり、様々なカテゴリーの動画をキュレーションしたりすることも可能です。Facebookは従来、これらの業務を委託企業に委託してきたため、今回の措置はコスト削減に繋がる可能性があります。
現在実施中のテストでは、このAIは有望な結果を示しています。ホッケー、バスケットボール、卓球などのスポーツの映像を見せると、競技を正確に識別できます。野球とソフトボール、ラフティングとカヤック、バスケットボールとストリートボールなど、様々な違いを判別できます。

Facebookの背後にあるAI
Facebook内には、Language Technologyと呼ばれる別のグループがあり、翻訳、音声認識、自然言語理解の開発に注力しています。LeCun氏が所属するFAIRは、FacebookのAI推進における研究部門であり、Language Technology(応用機械学習部門傘下)は、実際にソフトウェアを展開する部門の一つです。
彼らは FAIR と協力しながらも、開発と展開においては独自に取り組んでおり、その作業によって 493 件のアクティブに使用されている翻訳方向が開発されました (英語からフランス語、フランス語から英語は 2 つの方向としてカウントされます)。
Facebookは世界をよりオープンで繋がったものにするという理念を掲げており、言語サービスは自然な流れです。ユーザーの半数以上は英語を話しませんが、Facebookのコンテンツの大部分は英語で構成されていると、言語テクノロジー部門の責任者であるアラン・パッカー氏は言います。
これらの翻訳サービスは3億3000万人が利用しており、最も頻繁にアクセスされるのは「翻訳を見る」ボタンです。もしあなたが最初に翻訳ボタンをクリックしたなら、おめでとうございます。あなたは人工知能を操作したことになります。最初のクリックでサーバーへの翻訳リクエストが開始され、他のユーザーのためにキャッシュされます。パッカー氏によると、シャキーラの投稿はほぼ瞬時に翻訳されます。チームはコンテンツのネイティブ翻訳も展開しており、「原文を見る」ボタンが表示されます。
この役割において人工知能が必要なのは、「愚かな」翻訳は人間同士のやり取りを理解するのに役に立たないからです。不適切な構文を生成し、慣用句を誤解し、スラングを参照できません。これは、かつてのGoogle翻訳のような直接的な逐語訳の欠陥です。
パッカー氏は、比喩表現は特に難しいが、根底にある意味を理解する AI なら理解できるだろうと語る。
「『ホットドッグ』というフレーズを、そのままフランス語に直訳しても意味が通じません。『Chaud chien(暑い)』はフランス人には何の意味もありません」とパッカー氏は言う。「それに、私がスキーをしている写真があって、『今日はホットドッグをするんだ』と言ったとしても、ホットドッグが見せびらかすという意味だと理解するのは本当に難しいんです」
この理解はまだ大規模ではありませんが、初期の結果は、それが克服不可能な課題ではないことを示唆しています。パッカー氏は、重要なのは比喩や慣用句を理解することではなく、それらを理解すべきでないタイミングを認識することだと述べています。
AIは適応性に優れており、スラングを迅速に学習できます。言語技術チームは最近、フランスのサッカーファンが「wow」を表す際に新しいスラングを使用していることを知り、その公開データでニューラルネットワークを学習させた結果、そのテキストを確実に翻訳できるようになりました。現在、Facebookの語彙を毎日新しいデータで学習させることで拡張していますが、すべての言語は現在毎月更新されています。
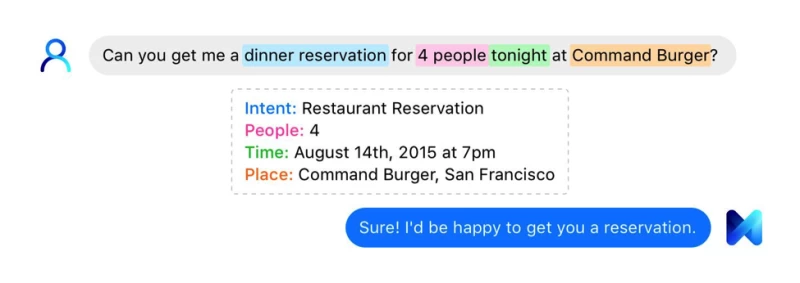
フェイスブックM
Siri、Cortana、Google Nowといったデジタルパーソナルアシスタントは、もはや当たり前の存在です。しかしFacebookは、新しいAIパーソナルアシスタント「M」で異なるアプローチを採用しました。Mは、スマートフォンの枠を超えた複雑なタスク実行機能を提供します。Siriはテキストメッセージを送信できますが、Mはフライトの予約や旅行プランの作成が可能です。開発過程では、Facebookの社員がMを使って引っ越し業者による自宅訪問査定のスケジュールを立てることさえありました。(ただし、Mではタバコ、アルコール、エスコート、銃器の購入はできません。)
Facebook Mの基盤は、今年初めに買収されたスタートアップ企業Wit.aiから来ています。同社は副社長デビッド・マーカス率いるMessengerチームに加わり、今月初めにMを発表しました。
Facebook内でWit.aiチームを率いるアレックス・ルブラン氏は、人工知能(AI)はMを一般的なタスクの遂行能力を向上させるだけでなく、乳幼児との旅行や利用停止日など、非常に特殊なケースにも対応可能にすると述べています。これはまた、AIの進化に伴いMの機能も向上することを意味します。ルブラン氏は、たとえ3年後でも、Mがケーブル会社やDMVに電話をかけ、ユーザーを待たせることができるようになることを期待しています。
「M のようなサービスの真の付加価値は、たとえそれが少々特殊であったり、変わった要求であっても、それに応えることができることです」と LeBrun 氏は言います。「たとえそれが複雑であったり、主流のケースでなかったりしても、M はそれを実現します。」
Mは学習しながら進んでいきます。現時点では、単独で動作できるほど堅牢ではありません。「AIトレーナー」のチームがプログラムと連携し、Mが理解できないリクエストがあった場合は、トレーナーが代わりに処理を行います。Mは人間のトレーナーの行動から学習し、その手法を以降のリクエストに適用できます。ルブラン氏によると、プログラムにはランダム性の要素も組み込まれており、人間の学習に近づけるとのこと。つまり、よくあるタスクでも、より効率的に新しい方法を見つけようとすることがあるということです。
「AIトレーナー」は新しい職種であり、Facebook自身もまだ模索中です。しかし、研究者やエンジニアではなく、カスタマーサービスの経験を持つ人材向けの仕事だとFacebookは述べています。時間が経つにつれて、Facebookはどれだけのリクエストに人間の介入が必要かを評価できるようになるでしょうが、最終的には人間が全く必要なくなることを期待しています。
ただし、これらは開発プロセスに不可欠です。その役割は 2 つあり、品質管理の最後の防衛線として機能し、AI に教えることです。
人間の知能をゲートキーパーとして活用することで、MはFAIR開発のサンドボックスとして活用できます。「テストすべきものがあれば、すぐにMで再現されます。私たちのトレーニングと監督のもとで、リスクは全くありません」とルブラン氏は言います。
M プラットフォームは完全に Wit.ai のプラットフォーム (主に Facebook 以前に開発) 上に構築されていますが、FAIR はパーソナル アシスタント AI と対話するユーザーから収集されたディープラーニング データも使用します。
Facebookコミュニティ
「私たちの研究はオープンに行われています。ほぼすべての研究成果は公開されており、私たちが書いたコードの多くはオープンソース化されています」とルカン氏は語る。これらの出版物は、Facebookの研究サイトだけでなく、コンピューターサイエンス、数学、物理学の研究論文を収蔵するライブラリであるArXivでも閲覧可能だ。

これは人工知能コミュニティの多くに当てはまります。ルカン氏は、AI開発用のC++ライブラリであるTorchの開発において中心人物の一人です。Facebookの他のチームメンバーと共に、TwitterやGoogleのDeepMindの研究者と協力し、Torchを誰にとってもより良いツールにするために尽力しています。(現在この分野の専門家である多くの人も、かつてルカン氏の教え子でした。)
ルカン氏によると、彼らが今後発表するあらゆる成果、例えば医用画像診断や自動運転車に統合できるような研究成果などは、この分野の発展のために自由に利用できるとのことだ。Facebookが行う研究はFacebookユーザーにとって重要だが、研究チームの根幹は、機械で知能をより良く模倣する方法に関する人類の集合的知識の深化を目指している。
これが、Facebook が人工知能コミュニティの重要な一部である理由であり、コミュニティ自体が非常に重要である理由です。
「ハリウッド映画で見るような、アラスカの孤高の人物が、誰にも真似できないほど完全に機能するAIシステムを発明するというシナリオは、全く不可能です」とルカン氏は述べた。「これは現代における最大かつ最も複雑な科学的課題の一つであり、単独の組織、たとえ大企業であっても、単独で解決できるものではありません。研究開発コミュニティ全体の協力が不可欠です。」
