

強力な人工知能ソフトウェアをオープンソース化し、世界中の誰もが使えるようにするというのは、まるでSF映画のワンシーンのようですが、GoogleとMicrosoftはここ数ヶ月でまさにそれを実現しました。そして今、Facebookはさらに一歩踏み出し、強力なAIコンピューターハードウェア設計を世界に公開しています。
これは大きな動きです。なぜなら、ソフトウェア プラットフォームによって AI 研究が確かに容易になり、複製や共有が容易になる一方で、強力なコンピューターがなければプロセス全体がほぼ不可能だからです。
Facebookは本日、サーバー設計をオープンソース化すると発表しました。同社によると、サーバーは従来の2倍の速度で動作するとのことです。Big Surと呼ばれるこの新設計は、CPU(中央処理装置)、ハードドライブ、マザーボードといった従来のコンピューター部品に加え、8基の高性能グラフィック処理装置(GPU)を搭載しています。Facebookによると、新しいGPUにより、研究者は機械学習モデルのサイズと速度を2倍に拡張できるとのことです。
なぜそれが重要なのか
画像や音声を定期的に処理することは、一般消費者向けの機器にとって負担が大きすぎる場合があります。一部の人工知能は、1,000万枚もの画像を分解して学習する必要があります。この「トレーニング」と呼ばれるプロセスには、高度な計算能力が必要です。
まず、基本事項を確認しましょう。AI の裏側は複雑で気が遠くなるような話になることがあります。人工知能とは、人間の思考や推論を模倣する人工システムを作成するためのさまざまなアプローチの総称です。これまでにもさまざまなアプローチがありましたが、現在最も人気のある方法は、ディープラーニング用のさまざまな種類の人工ニューラル ネットワークです。これらのネットワークは、情報を出力する前にトレーニングを行う、つまり例を示す必要があります。コンピューターに猫が何であるかを学習させるには、おそらく何百万枚もの猫の写真を見せる必要があります (ただし、Facebook の手法によりその数は大幅に削減されています)。ニューラル ネットワークは、ピクセルなどの小さな情報を個別に処理できる数学単位の仮想クラスターであり、これらを組み合わせて階層化することで、はるかに複雑なタスクを処理できます。
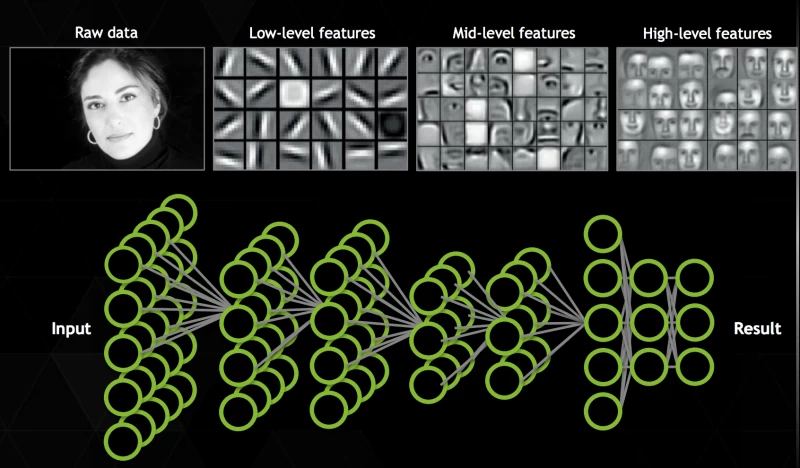
これは、何百万枚もの写真、フレーズ、あるいは音声データを、異なる抽象度を持つ、おそらく何百万もの人工ニューロンによって分解し、分析する必要があることを意味します。従来のコンピューターの部品でこの作業に使用できるものを挙げると、プロセッサ(CPU)とグラフィックス・プロセッサ・ユニット(GPU)の2つの選択肢があります。
CPUとGPUの違い
現代のコンピュータの「頭脳」とも言えるCPUは、いくつかの一般的なコンピューティングタスクを処理するのに最適です。CPUのコア数は比較的少なく(コンシューマー向けコンピュータやスマートフォンでは4~8個)、各コアはより大容量のキャッシュメモリを備えており、1つの処理を何度も繰り返し実行できます。CPUは、処理に必要なデータをコンピュータのランダムアクセスメモリ(RAM)から取得します。
GPUはその逆です。サーバー向けのGPUは1つで数千個のコアを搭載でき、メモリ容量は少なく、小さな繰り返しタスク(グラフィックスのレンダリングなど)の実行に最適化されています。人工知能の話に戻ると、GPUの多数のコアにより、より多くの計算を同時に実行でき、全体の処理速度が向上します。かつてはCPUがこの種の高負荷処理の主役でしたが、FacebookのAIリサーチ部門エンジニアリングディレクター、セルカン・ピアンティーノ氏によると、大規模プロジェクトではGPUで計算するよりも多くのネットワークチップが必要になったとのことです。
「GPUが提供するメリットは、一箇所に集約された膨大な計算処理能力です」とピアンティーノ氏は述べた。「現時点では、私たちが関心を持つ多くのネットワークにとって、GPUは最適な選択肢です。」
Facebookによると、Big Surは様々なメーカーのGPUに対応しているが、特に最近リリースされたNvidiaのモデルを使用しているという。Nvidiaは、自社製品を人工知能研究に重点的に投入している。画像トレーニングにおけるCPUとGPUの性能比較テストでは、デュアル10コアIvy Bridge CPU(つまり非常に高速)が256枚の画像を2分17秒で処理した。サーバー向けK40 GPUの1つでは、同じ画像をわずか28.5秒で処理した。そして、FacebookがBig Surで使用している新しいモデル、NvidiaのM40は、実際にはさらに高速だ。
多くのNvidiaデバイスには、Compute Unified Device Architecture(CUDA)プラットフォームが搭載されています。これにより、開発者はCやC++などのネイティブコードをGPUに直接記述し、コアを並列に、より正確に制御することができます。CUDAは、Facebook、Microsoft、Baiduなど、多くのAI研究センターで定番の技術です。
人間の脳を複製する?
GPUは現代のAIの主力ですが、一部の研究者は現状のコンピューティングでは解決できないと考えています。連邦政府の資金援助を受けるDARPA(国防高等研究計画局)は、2013年にIBMと提携し、SyNapseプログラムを開始しました。このプログラムの目標は、入力を受け取るという行為そのものがハードウェアに学習させる、自然に学習する新しいタイプのコンピュータチップの開発でした。その結果生まれたのが、2014年に発表された「ニューロモルフィック」チップ、TrueNorthです。
TrueNorthは54億個のトランジスタで構成され、100万個の人工ニューロンに構造化されています。人工ニューロンは2億5600万個の人工シナプスを形成し、データを受信するとニューロンからニューロンへと情報を伝達します。データはニューロン間を伝わり、ネットワークで利用可能な情報に変換できるパターンを生成します。

ヨーロッパでは、研究チームがFACETS(Fast Analog Computing with Emergent Transient States)と呼ばれるプロジェクトに取り組んでいます。このチップは20万個のニューロンと5000万個のシナプス結合を備えています。IBMとFACETSチームは、このチップをスケーラブルに設計しました。つまり、並列処理によって計算能力を大幅に向上させることができるのです。IBMは今年、48個のTrueNorthチップをクラスター化し、4800万個のニューロンからなるネットワークを構築しました。MIT Technology Reviewによると、FACETSは10兆個のシナプスを持つ10億個のニューロンを実現することを目指しています。
この数字をもってしても、860億個のニューロンと100兆個のシナプスを持つとされる人間の脳を再現するにはまだ遠い。(IBMは以前のTrueNorthの試験でこの100兆という数字を達成したが、チップの動作速度は実時間の1542倍遅く、96ラックのスーパーコンピューターが必要だった。)
Knowm の創設者であり、DARPA SyNapse の卒業生でもある Alex Nugent 氏は、特殊な種類のメモリスタでコンピューティングの未来をもたらそうとしており、それがトランジスタで動作する CPU、GPU、RAM に取って代わるだろうと述べている。
メモリスタは、1971年にコンピュータ科学者レオン・チュアが「失われた回路素子」として初めて理論を提唱して以来、テクノロジー業界のユニコーンとして君臨してきました。理論的には、メモリスタは現代のコンピュータの構成要素である従来のトランジスタの代替として機能します。
トランジスタは2つの状態(オンまたはオフ)を取ります。単純化すると、コンピューターはオンとオフの間を変化するトランジスタの膨大な配列に過ぎません。メモリスタは電流を用いて金属の抵抗値を変化させるため、これらの値に高い柔軟性を持たせることができます。トランジスタのような2つの状態ではなく、メモリスタは理論上4つまたは6つの状態を持つことができ、メモリスタの配列が保持できる情報の複雑さは倍増します。
生物学的効率
ニュージェント氏は、ボイシ州立大学のハードウェア開発者クリス・キャンベル氏と協力し、彼がAHaH(反ヘビアン・アンド・ヘビアン)学習と呼ぶ手法で動作する特定のチップを実際に開発しました。この手法では、メモリスタを用いて脳内のニューロンの連鎖を模倣します。メモリスタは、印加電圧に応じて抵抗値を双方向に変化させる能力を持ち、これはニュージェント氏によると、ニューロンが自身の微小な電荷を伝達する方法と非常に似ています。これにより、メモリスタは使用に合わせて適応することができます。メモリスタの抵抗値は自然なメモリとして機能するため、メモリスタは、一部の研究者がフォン・ノイマン・ボトルネックと呼ぶ、プロセッサとRAM間のデータ転送時に発生するデータ処理の限界を打ち破ることができるとされています。

「AHaHコンピューティングとは、『この構成要素を取って、そこから構築していこう』というものです」とニュージェント氏はポピュラーサイエンス誌のインタビューで述べた。「基本的にこれらの『ニューロン』を活用し、それらを様々な方法で接続し、その出力を様々な方法で組み合わせることで、学習操作が可能になります。」
このように、ニュージェント氏は、この研究が一般的なコンピューティングに適用できるだけでなく、特に機械学習に向けられていると考えています。
「今日既に実現可能な密度をメモリスタと組み合わせ、それを活用するための理論と組み合わせ、チップを三次元的に積み重ねれば、生物学的効率が実現します」とニュージェント氏は述べた。「最終的に得られるのは、インテリジェントなテクノロジーです。」
