
1900年代初頭、ドイツの調教師であり数学者でもあったヴィルヘルム・フォン・オステンは、自分の馬が数学を解けることを世界に発表しました。フォン・オステンは長年にわたりドイツ各地を巡り、この現象の実演を行いました。愛馬の「クレバー・ハンス」に簡単な方程式を解かせたところ、ハンスは蹄を叩いて正解を答えました。2足す2?なんと4回も叩いたのです。
しかし、科学者たちはハンスがフォン・オステンの主張するほど賢いとは信じなかった。心理学者カール・シュトゥンプフは、「ハンス委員会」と呼ばれる大規模な調査を行った。その結果、賢いハンスは方程式を解くのではなく、視覚的な合図に反応していることが判明した。ハンスは正しい数字までタップすると、トレーナーと観客が歓声をあげるのが常だった。そして、彼はタップをやめた。トレーナーの表情が見えなくなると、タップを繰り返すのだった。
コンピュータサイエンスは今日、ハンスから多くのことを学べます。急速に発展する研究分野は、これまでに生み出された人工知能のほとんどは、正しい答えを出すには十分な学習はしているものの、情報を真に理解できていないことを示唆しています。つまり、簡単に人を騙せるということです。
機械学習アルゴリズムは、瞬く間に人類の群れを見通す羊飼いへと変貌を遂げました。このソフトウェアは、私たちをインターネットで繋ぎ、メールにスパムや悪意のあるコンテンツがないか監視し、近い将来には車の運転も担うようになるでしょう。このソフトウェアを欺くことは、インターネットの基盤を根本的に揺るがすものであり、将来的には私たちの安全と安心にとってさらに大きな脅威となる可能性があります。
ペンシルベニア州立大学からGoogle、そして米軍に至るまで、小規模な研究者グループが、人工知能システムに対して実行されうる潜在的な攻撃を考案し、その防御に取り組んでいます。研究で提示された理論では、攻撃者は自動運転車の認識内容を改変することが可能です。あるいは、あらゆるスマートフォンの音声認識機能を起動させ、マルウェアが仕込まれたウェブサイトにアクセスさせ、人間にはホワイトノイズにしか聞こえないようにすることも考えられます。あるいは、ウイルスをファイアウォールをすり抜けてネットワークに侵入させることも可能です。

この方法では、無人運転車の操縦をするのではなく、実際には存在しない画像のような幻覚を無人運転車に見せるのです。
これらの攻撃は、敵対的サンプル(人間の視聴者には普通に見える画像、音声、あるいはテキストなど)を利用しますが、機械は全く別のものとして認識します。攻撃者が加える小さな変更によって、ディープニューラルネットワークは表示されているものについて誤った結論を導き出す可能性があります。
「セキュリティ上重要な決定を下すために機械学習を使用するシステムは、こうした種類の攻撃に対して潜在的に脆弱である」と、敵対的機械学習攻撃を研究するバークレー大学の研究者、アレックス・カンチェリアン氏は述べた。
しかし、人工知能開発の初期段階でこのことを把握することで、研究者たちはギャップを埋める方法を理解するためのツールを得ることになります。すでにその取り組みを始めている研究者もおり、そのおかげでアルゴリズムの効率が向上したと述べています。
今日の主流のAI研究の多くは、機械学習というより広範な分野を基盤とするディープニューラルネットワークです。機械学習技術は、微積分と統計を用いて、メールのスパムフィルターやGoogle検索など、私たちが日常的に利用するソフトウェアを開発しています。過去20年間、研究者たちはこれらの技術をニューラルネットワークと呼ばれる新しい概念に適用し始めました。これは、人間の脳を模倣することを目的としたソフトウェア構造です。その基本的な考え方は、数千もの小さな方程式(「ニューロン」)にコンピューティングを分散させるというものです。ニューロンはデータを受け取り、処理し、数千もの小さな方程式からなる別の層に渡します。
これらの人工知能アルゴリズムは、機械学習と同じ方法で学習します。つまり、人間が学習する方法と同じです。例を見せられ、それと関連付けるためのラベルが与えられます。コンピューター(または子供)に猫の写真を見せ、「これが猫の姿です」と言えば、アルゴリズムは猫が何であるかを学習します。異なる猫、あるいは異なる角度の猫を識別するには、コンピューターは数千から数百万枚の猫の写真を見る必要があります。
研究者たちは、敵対的サンプルと呼ばれる意図的に欺瞞的なデータを使ってこれらのシステムを攻撃できることを発見した。
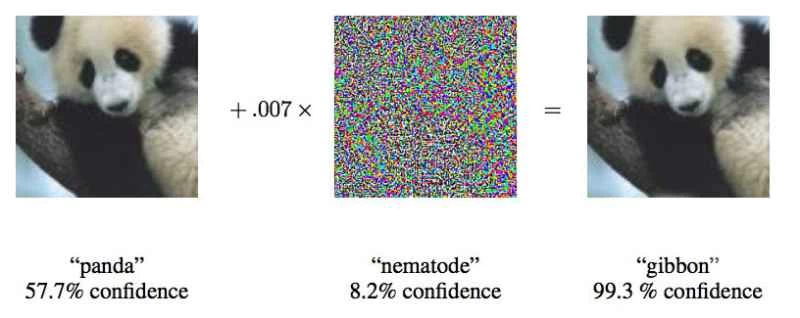
「明らかにスクールバスの写真を見せて、それがダチョウだと思わせるのです」と、敵対的事例に関する研究の多くを主導してきたグーグルの研究者、イアン・グッドフェロー氏は言う。
研究者たちは、ディープニューラルネットワークに入力する画像をわずか4%改変するだけで、97%の成功率で画像を誤分類させることに成功しました。ネットワークがどのように画像を処理しているかを知らなくても、85%近くの精度でネットワークを欺くことができました。後者の研究、つまりネットワークの構造を知らなくてもネットワークを欺く方法は、ブラックボックス攻撃と呼ばれます。これは、ディープラーニングシステムに対する機能的なブラックボックス攻撃に関する最初の研究であり、現実世界では最も起こり得るシナリオであるため、重要な研究です。
論文では、ペンシルベニア州立大学、Google、そして米国陸軍研究所の研究者たちが、開発者向けオンラインツールMetaMind上で動作する画像分類ディープニューラルネットワークに対して実際に攻撃を行った。研究チームは攻撃対象のネットワークを構築・学習させたが、攻撃アルゴリズムはネットワークのアーキテクチャとは独立して動作した。この攻撃アルゴリズムによって、ブラックボックスアルゴリズムに「何か別のものを見ている」と思わせることに成功し、その精度は最大84.24%に達した。

機械に誤った情報を提示する行為自体は目新しいものではないが、10年間敵対的機械学習を研究してきたバークレー大学教授のダグ・タイガー氏によると、この攻撃手法はより単純な機械学習からより複雑なディープラーニングへと応用されてきたという。悪意のある攻撃者は長年にわたり、スパムフィルターなどにこの手法を利用してきた。
タイガー氏の研究は、機械学習ネットワークに対する敵対的攻撃に関する2006年の論文(tygar/papers/Machine_Learning_Security/asiaccs06.pdf/)に端を発しており、2011年にカリフォルニア大学バークレー校とマイクロソフトリサーチの他の研究者らと共同でその論文を拡張しました。ディープラーニングへの応用を開拓したGoogleチームは、この攻撃の可能性を発見してから2年後の2014年に、この攻撃に関する最初の論文を発表しました。彼らは、この攻撃が実際に可能であり、例外的なものではないことを確認したかったのです。2015年には、ネットワークを保護し、より効率的にする方法を発見した別の論文を発表しました。その後、イアン・グッドフェロー氏は、ブラックボックス攻撃を含むこの分野の他の論文のコンサルタントを務めています。
セキュリティ研究者は、信頼できない情報というより広い概念を「ビザンチンデータ」と呼んでおり、この研究の積み重ねを経てディープラーニングに至りました。「ビザンチンデータ」という用語は、ビザンチン将軍問題に由来しています。これはコンピュータサイエンスにおける思考実験で、将軍の集団が伝令によって攻撃を調整しなければならないものの、仲間内に裏切り者がいるかどうか分からないというものです。そのため、仲間から提供される情報を信頼することができません。
「これらのアルゴリズムはランダムノイズを処理するために定義されており、ビザンチンデータを処理するように作られているわけではありません」とタイガー氏は言う。
これらの攻撃がどのように機能するかを理解するために、グッドフェロー氏はニューラルネットワークを散布図のように想像することを提案しています。
散布図上の各点は、ネットワークによって処理されている画像の1ピクセルを表しています。ネットワークは通常、各点の位置を最もよく反映した線をデータに引こうとします。これは一見すると少し複雑ですが、ネットワークにとって各ピクセルは複数の値を持つためです。実際には、これは複雑で多次元のグラフであり、コンピューターはそれを整理しなければなりません。
しかし、散布図という単純な例えでは、データに引かれた線の形状が、ネットワークが見たと考えるものを決定します。これらのシステムをうまく攻撃するには (入力を誤分類するように強制することによって)、研究者はこれらのポイントのごく一部を変更して、実際には存在しない結論をネットワークが導き出すように誘導するだけで済みます。これらの変更されたポイントは、ネットワークが馴染みのあるものと見なす範囲を超えているため、間違いを犯します。バスをダチョウに見せる例では、スクールバスの写真には、ネットワークが馴染みのあるダチョウの写真に特有のパターンになるように設計されたピクセルが点在しています。目に見える輪郭ではありませんが、アルゴリズムがデータを処理して簡素化すると、極端なダチョウのデータポイントが分類の有効なオプションと見なされます。ブラックボックスのシナリオでは、研究者は入力をテストして、アルゴリズムが特定のオブジェクトをどのように認識したかを確かめました。
研究チームは、画像分類器に偽の入力を与え、機械がどのような判断を下すかを観察することで、アルゴリズムをリバースエンジニアリングし、自動運転車に搭載され、一時停止標識を譲歩標識と認識する画像認識システムを欺くことに成功しました。そして、この脆弱性の仕組みを解明することで、機械に望むものを何でも認識させる方法を考案しました。
研究者らは、この種の攻撃はカメラを迂回して画像システムに直接注入されるか、あるいは現実世界の標識に対して操作が行われる可能性もあると述べた。
しかし、コロンビア大学のセキュリティ研究者アリソン・ビショップ氏は、自動運転車に搭載されているシステムの種類によっては、この種の攻撃は非現実的かもしれないと述べている。もし攻撃者が既にカメラ映像にアクセスできていたなら、彼らは望むあらゆる情報を入力することができただろうと彼女は述べている。
「カメラへの入力をバイパスできれば、そんなに苦労する必要はありません」と彼女は言った。「停止信号を見せればいいんです」
カメラを迂回するのではなく、標識自体に歪みを描き込むというもう一つの攻撃方法も、ビショップ氏には無理があるように思える。彼女は、今日の自動運転車に使われているような低解像度のカメラが、標識のわずかな歪みを読み取ることができるとは考えにくいと見ている。

バークレー大学とジョージタウン大学の2つの研究グループが、SiriやGoogle Nowなどのデジタルパーソナルアシスタントに対し、人間の耳には認識できない連続音の形で音声コマンドを発行できるアルゴリズムの開発に成功しました。人間にとってはこれらのコマンドは単なるランダムなホワイトノイズに聞こえますが、AmazonのAlexaのような音声アシスタントに、所有者が意図しない動作を指示するために使用できる可能性があります。
ビザンチンオーディオ研究者の一人、ニコラス・カルリーニ氏は、彼らのテストではオープンソースのオーディオ認識装置、Siri、Google Now をアクティブ化することができ、その精度は 3 つとも 90 パーセント以上だったと述べています。
まるでSFに出てくるエイリアンの通信音のようだ。ホワイトノイズと人間の声が混ざり合った、聞き取れない音だが、命令としては全く認識できない。
この攻撃では、ノイズを聞き取ったスマートフォン(具体的にはiOSまたはAndroid端末をターゲットにする必要がある)が、知らないうちにノイズを再生するウェブページにアクセスさせられ、近くにある他のスマートフォンに感染させられる可能性があると、カルリーニ氏は述べている。同じシナリオで、ウェブページが密かにマルウェアをデバイスにダウンロードすることも可能だ。また、これらのノイズはホワイトノイズやBGMに紛れ、ラジオで再生される可能性もある。
こうした攻撃は、ほぼすべての入力に読み取り可能なデータや重要なデータが含まれていると考え、またあるものは他のものよりも一般的であると考えるよう機械が訓練されているために起こる可能性があるとグッドフェロー氏は言う。
ネットワークを騙して、ありふれた物体を見ていると錯覚させるのは簡単です。なぜなら、ネットワークはそれをもっと一般的に見ているはずだと考えているからです。だからこそ、グッドフェローとワイオミング大学の別のグループは、ホワイトノイズ(ランダムに生成された白黒画像)をネットワークに識別させることで、実際には何も存在しない画像を分類することに成功しました。
グッドフェロー氏の研究では、ネットワークに入力したランダムなホワイトノイズは、ほとんどの場合馬として分類されました。これは偶然にも、先ほど紹介した数学的才能に恵まれていない馬、クレバー・ハンスの話に戻ります。
グッドフェロー氏によると、これらのニューラルネットワークは実際には特定のアイデアを学習しているのではなく、正しいアイデアを見つけたときにそれを認識する方法を学習しているだけだという。この違いはわずかだが、重要である。基礎知識の欠如により、アルゴリズムにとって「正しい」結果(実際には誤った答え)を見つけるという経験を、悪意を持って容易に再現してしまうのだ。何が正しいのかを理解するには、機械は何が間違っているのかも理解しなければならない。
グッドフェロー氏は、画像分類ネットワークを自然な画像と加工された画像(偽物であると指定)の両方でトレーニングしたところ、攻撃の効率を 90 パーセント以上削減できただけでなく、ネットワークが本来のタスクをよりうまく遂行できることを発見しました。
「本当に珍しい敵対的事例を説明するよう強制し始めると、根底にある概念が何であるかについて、さらに強力な説明が出てくるかもしれません」とグッドフェローは言う。
2つの音声研究グループは、Googleの研究者と同じアプローチを用いて、ネットワークを再トレーニングすることで、自らの攻撃に対する言語認識システムのパッチ適用を行いました。攻撃効率を90%以上削減するという、Googleと同レベルの成果を達成しました。
この研究分野がアメリカ軍の関心を集めているのは当然のことです。実際、陸軍研究所はブラックボックス攻撃を含む少なくとも2つの最近の論文を後援しています。陸軍研究所は研究への資金提供に積極的ですが、これはこの技術が戦争での使用に向けて積極的に開発されていることを意味するわけではありません。広報担当者によると、研究が兵士の手に渡るまでには通常10年以上かかるとのことです。
米陸軍研究所の研究員であるアナントラム・スワミ氏は、敵対的攻撃に関する最近の論文に様々なレベルで関与してきた。陸軍の関心は、情報源の全てが適切に検証されているわけではない時代に、意図的に欺瞞的なデータを検知し、阻止することにある。スワミ氏は、大学やオープンソースプロジェクトが設置した公開センサーからアクセスできる膨大なデータに注目している。
「私たちは必ずしもすべてのデータを管理しているわけではありません。敵対者が私たちを騙し、欺くのはおそらくかなり容易でしょう」とスワミ氏は述べた。「その中には無害なものもあれば、そうでないものもあります。」
彼はまた、陸軍は自律型ロボット、戦車、その他の車両に大きな関心を持っているため、この研究は当然のことだと述べています。今これを研究することで、陸軍は敵対的な攻撃の可能性を回避できる戦場のシステム構築において、優位に立つことができるでしょう。
しかし、急速に成長しているディープニューラルネットワークを利用するグループは、敵対的攻撃の可能性を懸念すべきです。機械学習や人工知能システムはまだ初期段階にあり、セキュリティ監視の不備が深刻な結果をもたらしかねない危険な時代にあります。多くの企業が、非常に不安定な情報を人工知能システムに委ねていますが、それらは長年の検証に耐えていません。私たちのニューラルネットワークはまだ若すぎて、そのすべてを把握することはできません。
同様の見落としが、MicrosoftのTwitterチャットボットTayを瞬く間に大量虐殺的な人種差別主義者へと変貌させた。大量の悪意あるデータと、予想通りひどい「繰り返して」機能によって、Tayは当初のプログラミングから大きく逸脱してしまった。このボットは、野放しの粗悪な学習データに乗っ取られ、機械学習の実装が不十分な場合に何が起きるかを示す好例となっている。
カンチェリアン氏は、Google チームによる有望な研究があるにもかかわらず、これらの攻撃のいずれに対しても扉が完全に閉ざされたとは思っていないと述べている。
「少なくともコンピュータセキュリティの世界では、残念ながら攻撃者は常に私たちの先を進んでいます」とカンチェリアン氏は言う。「ですから、敵対的機械学習の問題をすべて再学習で解決したと言うのは少し危険です。」
