
言語とは繰り返しの繰り返しです。あなたが今読んでいる言葉はすべて人間によって作られ、その後、他の人間によって使われ、文脈や意味、そして言語の本質が創造され、強化されています。人間が機械に言語を理解させるように訓練すると同時に、機械に人間の偏見を模倣するように教えているのです。
「私たちが示し、証明できる主な科学的知見は、言語が偏見を反映しているということです」と、プリンストン大学情報技術政策センターのアイリン・カリスカン氏は述べています。「AIが人間の言語で訓練されれば、必然的にこうした偏見を吸収することになります。なぜなら、AIは世界の文化的事実や統計を反映しているからです。」
カリスカン氏と共著者のジョアンナ・ブライソン氏、アルヴィンド・ナラヤナン氏による研究は、先週サイエンス誌に掲載されました。彼らは基本的に、機械に人間の言語を理解するように訓練すると、機械は人間の言語に内在するバイアスも拾ってしまうことを発見しました。
人間の場合、バイアスを検査する最良の方法の一つは、潜在的連合テストです。このテストでは、「昆虫」のような単語を「快い」や「不快な」といった単語と関連付けてもらい、その関連付けにかかる時間(潜時)を測定します。人は昆虫を不快だとラベル付けするのは早いですが、快いとラベル付けするのは遅いため、このテストは関連付けの指標として有効です。
コンピュータの躊躇いをテストすることは実際にはうまくいかないため、研究者たちはコンピュータがどのような単語を他の単語と関連付けやすいかを調べる別の方法を見つけました。学生が馴染みのない単語の意味を、その単語の近くに現れる単語だけに基づいて推測するのと同じように、研究者たちはAIを訓練し、オンライン上で互いに近くに表示される単語同士を関連付け、そうでない単語は関連付けないようにしました。
それぞれの単語を三次元空間のベクトルとして想像してみてください。同じ文でよく使われる単語はベクトルに近い位置にあり、同じ文であまり使われない単語はベクトルから遠い位置にあります。2つの単語が近いほど、機械がそれらを関連付ける可能性が高くなります。例えば、「プログラマー」は「彼」や「コンピューター」に近いのに、「看護師」は「彼女」や「衣装」に近いと言うのは、言語における暗黙のバイアスを表しています。
コンピューターにこの種の言語データを与えて学習させるという概念は、新しいものではありません。スタンフォード大学のGlobal Vectors for Word Representation(この論文より前から存在していた)のようなツールは、関連する単語間の使用頻度に基づいてベクトルをプロットします。GloVeの単語セットには、20億件のツイートから抽出された270億語、2014年のWikipediaから抽出された60億語、そしてインターネットをランダムに検索して抽出された8400億語が含まれています。
「『『猫』の近くに『リーシュ』は何回出てくるか?」『『犬』の近くに『リーシュ』は何回出てくるか?『正義』の近くに『リーシュ』は何回出てくるか?」と尋ねれば、それが単語の特徴付けの一部になるでしょう」とブライソンは言った。「そして、これらのベクトルをコサインで比較することができます。『猫』は『犬』にどれくらい近いのか?『猫』は『正義』にどれくらい近いのか?」
潜在的連合テストが人間が無意識のうちに良い概念と悪い概念として考えていることを明らかにするのと同様に、異なる単語グループ間の平均距離の計算は、コンピュータが言語理解においてどのようなバイアスを示し始めているかを研究者に示しました。言語を理解するように訓練された機械が、花(心地よい)や昆虫(不快)に関する人間のバイアスを捉えたことは注目に値します。ブライソン氏は、もしそれが示されただけなら、これは意義深い研究になるだろうと述べました。しかし、研究はそれ以上の深いところまで掘り下げていました。
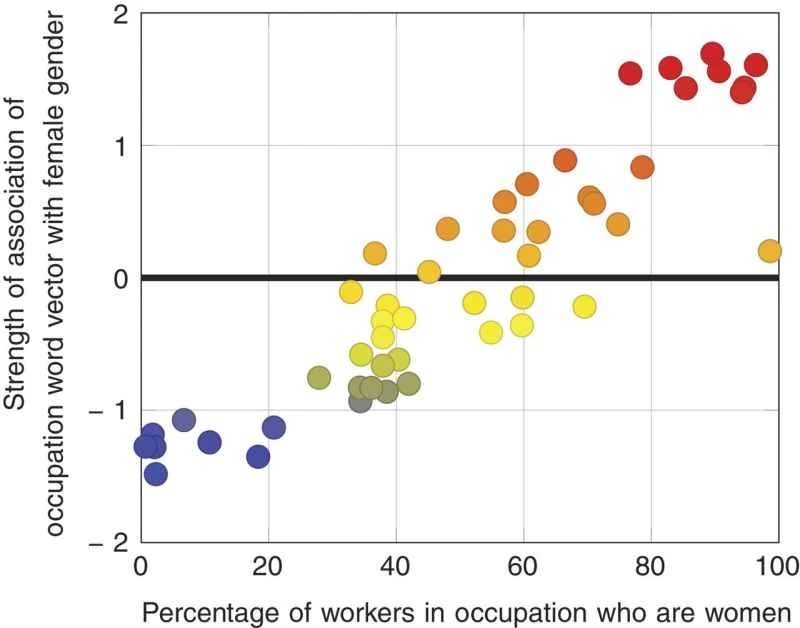
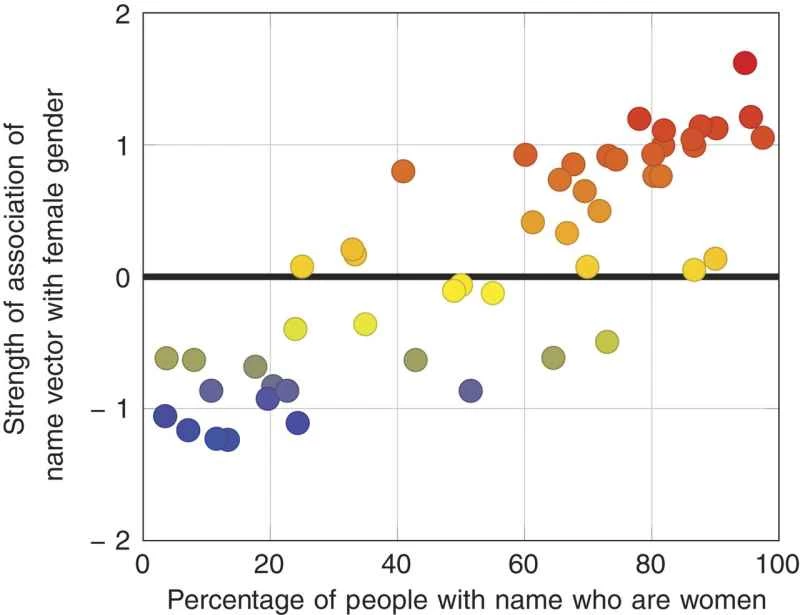
「2つ目のテストは、私たちの調査結果と公表されている統計データとの間の量を測定することです」とカリスカン氏は述べた。「2015年の労働統計局のデータを調べました。毎年、職業名と、その職業に就く女性の割合、例えば黒人アメリカ人の割合が公表されています。50の職業名の構成を調べ、男性または女性との関連性を計算したところ、労働統計局のデータと90%の相関関係があることがわかりました。これは非常に驚くべき結果でした。なぜなら、これほどノイズの多いデータからこれほどの相関関係を見つけられるとは思っていなかったからです。」
つまり、コンピューターは職業関連の言葉を特定の性別や民族集団と関連付けることで、人種差別や性差別を察知しているのです。論文で強調されている例の一つは「プログラマー」です。これは英語では性別を表す言葉ではありませんが、その使用法によって男性の職業というニュアンスを帯びるようになりました。
「プログラマーと言うとき、男性を意味するのか女性を意味するのか、私たちは考えていませんでした」とブライソンは言う。「しかし、その言葉が通常使われる文脈では、その通りだということが分かりました。」
GloVeのような、実際に使われている言語のデータセットで訓練された機械は、この関連性を捉えるでしょう。なぜなら、それが現在の文脈だからです。しかし、これは将来の研究者が、同じ人間のバイアスが組み込まれているため、そのデータの使用方法について慎重になる必要があることを意味します。Caliskan氏は、中立的な言語編集基準を持つWikipediaの単語セットでツールを訓練したところ、インターネットから抽出したより大規模な単語セットで発見したのと同じバイアスが含まれていることを発見しました。
「偏見に気づき、偏見をなくすためには、それを定量化する必要があります」とカリスカン氏は述べた。「言語に偏見はどのようにして生まれるのでしょうか?人々は言語に触れる機会から、偏見のある連想を抱き始めるのでしょうか?それを知ることは、偏見の少ない未来への答えを見つける助けにもなるでしょう。」
一つの答えは、他の言語に目を向けることかもしれません。この研究はインターネット上の英語の単語に焦点を当てているため、単語の使用において発見されたバイアスは、インターネットにアクセスできる英語圏の人々が一般的に持つバイアスです。
「私たちは様々な言語を研究し、その文法に基づいて、それがジェンダー・ステレオタイプや性差別に影響を与えているかどうかを解明しようとしています。文法そのものがジェンダー・ステレオタイプや性差別に影響を与えているのです」とカリスカン氏は述べた。「ジェンダーのない言語もあれば、少しジェンダー化が進んでいる言語もあります。英語にはジェンダー化された代名詞がありますが、ドイツ語のように名詞にジェンダー化が見られる言語では、よりジェンダー化が進んでおり、さらにジェンダー化が進むこともあります。スラブ語族にはジェンダー化された形容詞や動詞さえあります。これが社会におけるジェンダーバイアスにどのような影響を与えているのか、私たちは疑問に思っているのです。」
言語に偏見がどのように入り込むかを理解することは、明示的な定義以外に人々が言葉にどのような暗黙の意味を加えるかを理解する方法でもあります。
「ある意味、これは意識について考える助けになっています」と、この研究の著者の一人であるジョアンナ・ブライソンは語った。「意識の有用性は何でしょうか? 世界の記憶を持ちたい、普段どんなことが起こるのかを知りたいと思うでしょう。それが意味記憶なのです。」
言語の可変性、つまり使用を通じて意味的コンテキストが形成される方法は、これがこの世界を理解する唯一の方法である必要はないことを意味します。
「新しい現実を創造したいのです」とブライソンは続けた。「人類は、女性が働き、キャリアを積むことができるほど、自分たちの環境が十分に整ったと判断しました。そして、それは全くもって妥当なことです。そして今、私たちは新たな合意を交渉できるのです。例えば、『単数形であっても、『プログラマーの彼』ではなく、『プログラマーの彼ら』と言う』といった具合です。なぜなら、人々にプログラマーになれないと感じさせたくないからです。
そして、人間の言語で機械をプログラミングする際に、こうした既存の偏見を考慮しなければ、偏見のない機械ではなく、人間の偏見を再現する機械が作られることになります。
「機械は中立的だと思っている人が多い」とカリスカン氏は言う。「機械は中立的ではない。機械学習のように、逐次的に意思決定を行うシーケンシャルアルゴリズムは、人間のデータセットで学習されている。そのため、人間のデータを提示し、反映させる必要がある。過去のデータにはバイアスが含まれているため、優れた学習アルゴリズムであれば、学習済みモデルにもそれらのバイアスが考慮される必要がある。十分な精度があれば、そうした関連性をすべて理解できる。機械学習システムは、見たものを学ぶのだ。」
