
私たちの周りでは、アルゴリズムが目に見えないところで働いています。音楽を推薦したり、ニュースを浮かび上がらせたり、癌の腫瘍を発見したり、自動運転車を実現したりしています。しかし、人々はそれらを信頼しているのでしょうか?
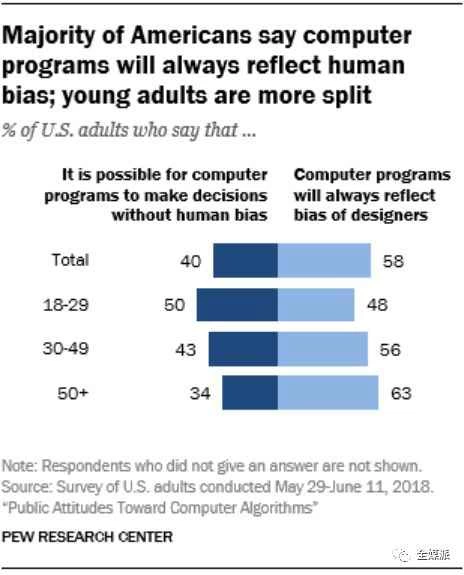
ピュー・リサーチ・センターが昨年実施した調査によると、そうではないようです。コンピュータプログラムは常に設計者のバイアスを反映するかという質問に対し、回答者の58%がそう考えると回答しました。この結果は、人々の生活への影響がますます大きくなると予想されるコンピューティング技術と、その影響を受ける人々との間に深刻な緊張関係があることを浮き彫りにしています。

特定の技術に対する不信感は、その受容と利用を阻害します。一方で、危険な技術に対する正当な不信感は良いことです。患者に放射線の過剰投与をもたらしたTherac-25ソフトウェアや、NASAの火星探査機喪失の原因となった誤った単位計算など、望ましくない結果をもたらす不適切なアルゴリズムの使用を排除することに反対する人はいません。一方で、ワクチン接種などの安全な技術に対する人々の不合理な恐怖感自体が危険となり得ます。技術を不信感を持つ人は、その恩恵を個人的に享受できないだけでなく、参加を拒否することで他の人々に悪影響を及ぼし、社会全体に悪影響を及ぼす可能性があります。
したがって、合理的な恐怖と非合理的な恐怖を区別し、後者を助長しないようにすることが重要です。特に世論に影響を与える立場にある場合はなおさらです。残念ながら、このピュー研究所の世論調査、あるいは少なくとも結果の報道方法は、状況を曖昧にしています。この調査では、アルゴリズムが意思決定を行う4つの異なるシナリオについて回答者に尋ねました。それは、個人の財務スコアの算出、仮釈放決定のための犯罪リスク評価、求職者の履歴書の審査、そして就職面接の分析です。リードグラフの見出しは、調査結果を要約しています。「アメリカ人の大多数は、コンピュータープログラムは常に人間の偏見を反映すると回答している。若い世代では意見が分かれている。」
この記述の問題点は、アルゴリズムの一般的な概念と特定の種類のアルゴリズムの概念を誤って同一視していることです。提示されたシナリオで使用されるアルゴリズムは機械学習によって学習されたものであり、本質的にはブラックボックスであり、そのロジックは内部的には意味を持たない数値の集合として表現されています。これらの機械学習アルゴリズムの問題は、事実上判読不可能であり、人間には理解できないことです。
対照的に、人間が作成したアルゴリズムは可読性があり、他の人間が理解できる言語で提供されます。これには、自然言語で記述された記述(レシピ、運転指示、ゲームのルール、家具の組み立て手順など)だけでなく、機械が実行できるプログラミング言語で書かれたプログラムも含まれます。
これら2種類のアルゴリズムの読みやすさと理解しやすさの違いは、アルゴリズムの信頼性を判断する上で非常に重要です。人間が作成したアルゴリズムが常に正しいというわけではありません。むしろその逆です。人間は誤りを犯すものであり、その成果物も誤りを犯す可能性があります。そして、アルゴリズムやソフトウェア全般にはバグが含まれていることで知られています。しかし、読みやすいアルゴリズムと読みにくいアルゴリズムの決定的な違いは、前者は効果的に修正できるのに対し、後者は修正が不可能であるということです。
料理が塩辛すぎる場合、レシピの中で塩が加えられている箇所を見つけて量を減らすことができます。また、運転中に間違った場所に誘導された場合、間違った方向を指し示して修正するのは簡単です。しかし、判読不能なアルゴリズムの場合は状況は全く異なります。誤った動作を観察しても、アルゴリズムの記述の中でその原因となっている箇所を特定できず、修正もできません。機械学習アルゴリズムのブラックボックス性は、これを効果的に阻止します。機械学習アルゴリズムの誤った動作を修正する唯一の方法は、新しいデータで再トレーニングすることですが、それによって別のバイアスが導入される可能性があります。
データの偏りはアルゴリズムにとって当然の懸念事項ですが、それは不正確なデータに基づいて判断を行うアルゴリズムに限るものです。アルゴリズムについて議論する際、特に責任の所在を特定し警鐘を鳴らす際には、判読可能なアルゴリズムと判読不可能なアルゴリズム(つまり機械学習によるアルゴリズム)を区別するよう注意する必要があります。
ピュー・リサーチ・センターの世論調査に戻ると、これも実際にはアルゴリズムであり、さまざまな人々の回答を入力として実行されていることに気づくだろう。誤解のないよう明確に述べると、採用された方法論に問題はなく、人々に尋ねられたシナリオも重要だが、結果の報告方法は誤解を招きやすく、無責任であると言えるだろう。皮肉なことに、シナリオ例の選択に偏りがあり、まさにそれが非難している現象の一例となっている。幸いにも、ピュー・リサーチ・センターの世論調査は人間が作成したものなので、欠陥を特定して修正することができる。簡単な修正方法は、見出しを変えて、人々は機械学習アルゴリズムを信頼していないと報じることだ。別の可能性としては、機械学習以外のアルゴリズムの例をいくつか提示し、それらに対する人々の回答も調査に組み込むことだ。
アルゴリズムに対する人々の態度をより正確に把握し、不必要な嫌悪感や誤ったパニックを招かないようにするために、アルゴリズムを判断する人は誰でも、人間が作成したものと機械学習によって作成されたものを区別する必要があります。世論調査員、ジャーナリスト、そして世論の測定や影響を与えることに携わるすべての人々は、アルゴリズムの性質をより深く理解することで恩恵を受けるでしょう。それは、世論調査の対象となる人々も同様です。
アルゴリズムに欠陥があるのは事実ですが、世論調査にも欠陥はあります。どちらにおいても、偏りを避けるよう努めましょう。
マーティン・アーウィグはオレゴン州立大学のコンピュータサイエンスのストレッチ教授であり、『 Once Upon an Algorithm: How Stories Explain Computing』の著者です。
このストーリーはもともとThe Readerに掲載されました。
